
As a self-confessed AI geek, I’m constantly on the lookout for new AI tools to integrate into my daily marketing workflows. And while it can be draining to be constantly retargeted with shallow ChatGPT wrappers, as a marketing pro in 2025, you simply can’t ignore the potential that AI tech has to drive creativity, productivity and augment the best sides of human-centric marketing strategies.
If you’re even a little bit tech-inclined, you will have struggled to avoid the shockwave that the launch of DeepSeek has made some 2 weeks ago. Even early last week, I overheard many colleagues discussing DeepSeek in breakout areas, in the kitchen and on calls. In fact, the way DeepSeek seems to have entered the public consciousness is remarkably similar to when ChatGPT launched in Nov 2022.
And so, as any self-respecting AI aficionado would do, I’ve decided to put the two AI heavyweights to the test, facing off against a relatively complex marketing prompt to see which outperforms the other.
TLDR: Take me to the results already! Click here
Rules of engagement
- Subscription – Free
- Interface – Web app
- Reasoning – On (where available)
- Models – o3-mini & DeepThink (R1)
- File upload 1 – .jpg Screenshot of Landing Page
- File upload 2 – 11 page “Tone of Voice Guidelines” PDF uploaded as a reference
The relatively complex prompt:

To put both AI apps to the test, I’ve constructed a relatively complex prompt asking each app to analyse a particular landing page URL and then provide UX, CRO and page content improvement recommendations while referencing a high-level ICP and a detailed Tone of voice guideline.
Prompts in situ
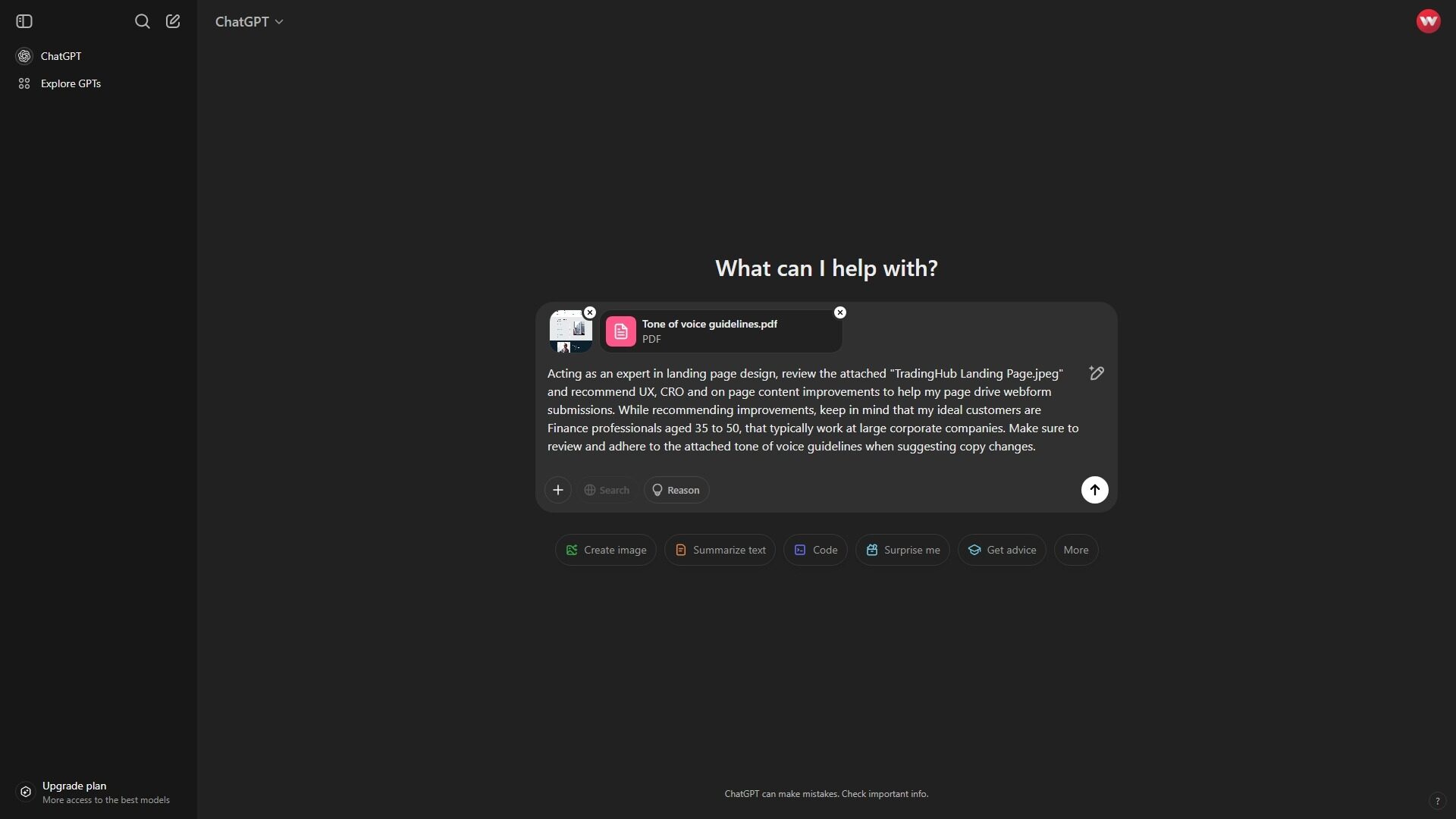
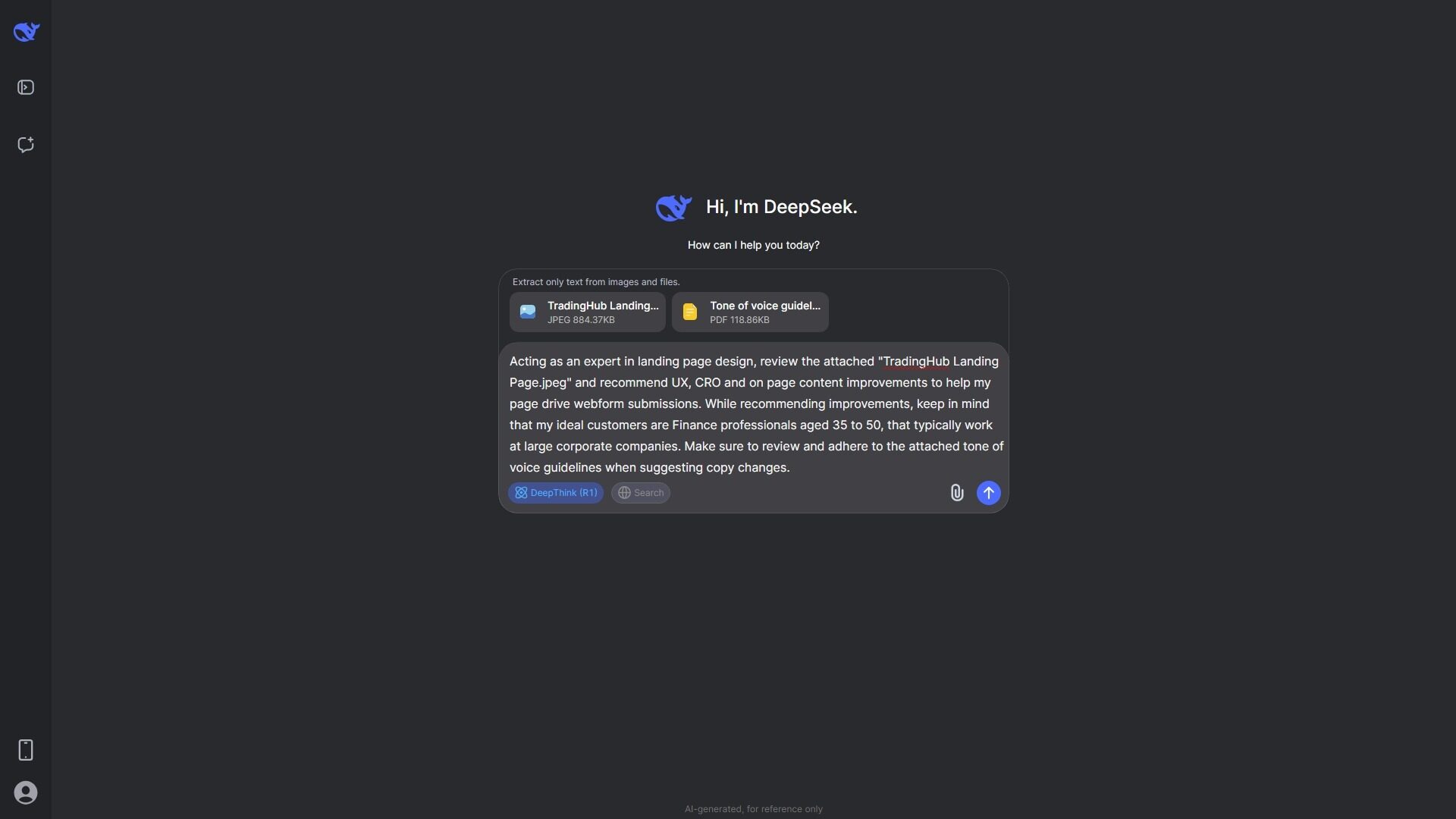
View the landing page: https://tradinghub.com/
Breaking down the outputs
ChatGPT
View the full prompt output here.
At the time of writing, ChatGPT has (just today) disabled the ability to utilise reasoning when referencing attachments. Not only does this prevent users from being able to read and analyse the model’s ‘thought’ process, but presumably this will inhibit the model’s capacity to generate prompts that equal DeepSeek’s outputs depth, accuracy and usefulness.
The output begins with a brief summary of the prompt and outlines the content of the proceeding output.

Key takeaway 🥡 0 out of 2 points – primarily due to the inability to apply reasoning and the ‘shallow’ prompt summary.
The second output section of the output outlines potential UX enhancements, highlighting perceived issues related to copy, UVP inclusion and CTA button prominence.
The recommended fixes are solid and based on reliable UX best practises. Additionally, the suggested changes to copy are reasonable, actionable, and would, in my opinion, improve the cognitive fluency of the page. The last suggestion off adding a secondary CTA feels unnecessary and less aligned with the notion of decreasing friction.

Key takeaway 🥡 2 out of 2 points – solid copy recommendations with reasonable CTA adjustments.
The next output section suggests that the navigation contains too many items and theorises that the scroll depth of the page is too long. While the reference to scroll depth seems partially reasonable, the comment regarding the number of menu items in plainly incorrect. As a result, the recommended fixes are poor.
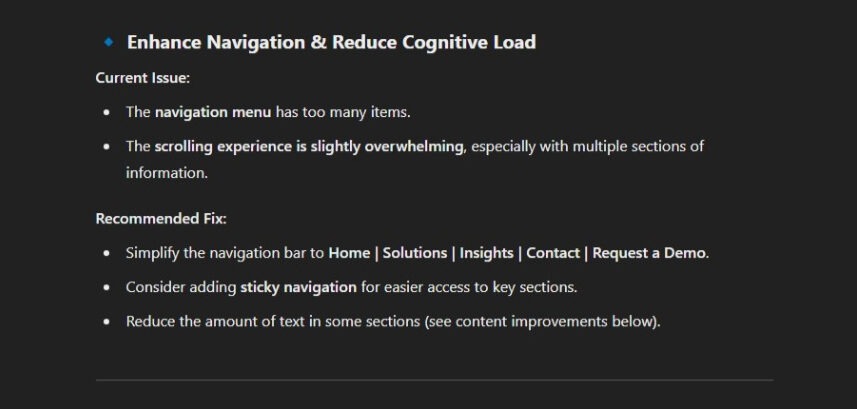
Key takeaway 🥡 0 out of 2 points – due to hallucination and questionable ‘tips’
The CRO optimisation section of the output suggests that the size of the customer testimonial is too small, a view I don’t think would be reasonably shared by an average user. The critique regarding the lack of recognisable clients and trust signals seems fair, however, the last recommended fix completely overlooks that the page already includes a link to a client case study.

The following ‘issues’ and recommended fixes lack relevancy, and the output completely hallucinates the inclusion of a non-existent form while suggesting generic optimisation tips
Key takeaway 🥡 1 out of 2 points. Fair comments regarding including well-known clients and trust signals.

Again, the proceeding suggestions simply feel generic and are unlikely to significantly move the needle when it comes to driving webform submissions (the key objective off the prompt).

Key takeaway 🥡 0 out of 3 points.
While concluding, the first two priorities of the output pass a basic sense check, however the output once again reinforces its prior hallucination regarding the ‘Demo Request Form’.
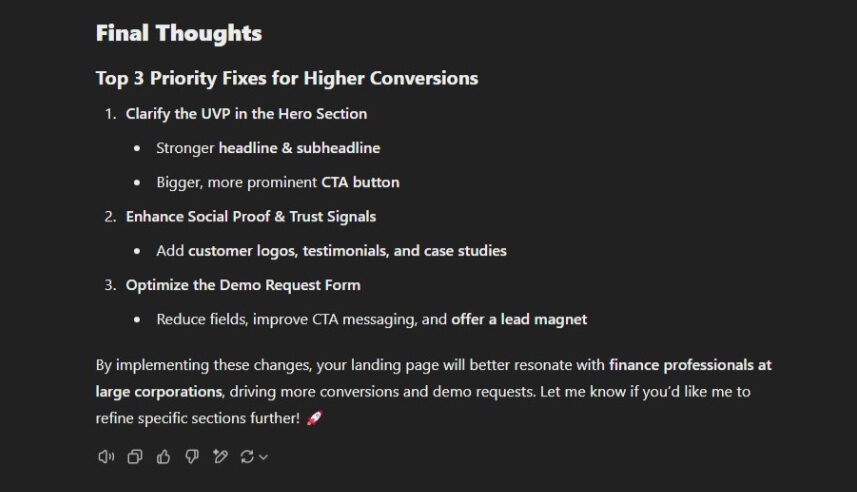
Key takeaway 🥡 2 out of 3 points.
DeepSeek
View the full prompt output here.
Full ‘reasoning’ has been available for DeepSeek users since launch, with no restriction on the type of prompts reasoning can be applied to. This allows users insight into the model’s ‘thought process’ meaning that we can assess the incremental steps the model takes when generating an output.
In the below we can clearly see the model methodically reviewing the landing page screenshot, highlighting at specific components and content areas inline with our prompt. It’s important to note that the reasoning section also clearly reference the Tone of Voice guidelines which we attached to the prompt, and considers changes related to that reference too.
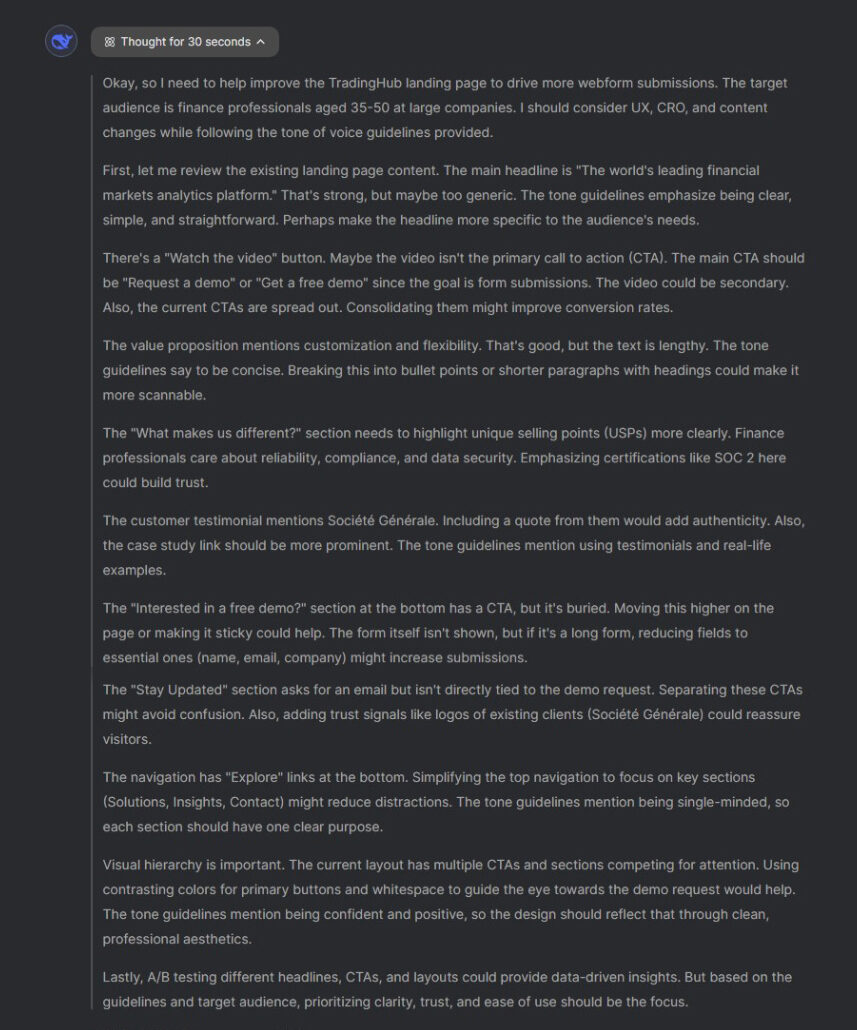
Key takeaway 🥡 2 out of 2 points – primarily due to the ability to apply reasoning and reference-specific analysis.
In the first clear difference between ChatGPT & DeepSeek’s outputs, the first output section from DeepSeek combines UX and CRO recommendations into a single prompt section. Another clear difference is the omittance of stated ‘issues’. While DeepSeek’s recommendations are mostly reasonable and actionable, it does feel like the absence of the stated issues leaves the user with less context regarding why a specific recommendation is being suggested.

Key takeaway 🥡 2 out of 4 points – primarily due to the omittance of stated ‘issues’ which would have provided greater context to the user.
Moving on to the “On-Page Content Improvement recommendations”, can see that DeepSeek is specifically referencing the Tone of Voice Guidelines PDF which we uploaded when suggesting headline and sub head copy amends, better still, the recommendation feels considered and the copy has a noticeable tone that nicely engages the ICP (Global Banks and Asset Managers). The inclusion of both the “Before” and “After” sections of copy make it easy to compare the recommendations with prior copy. While further suggestions are simple, such as using bullet lists to break up the text, they are useful and grounded in copywriting best practise.
The following 3rd and 4th recommendations propose incorporating a customer testimonial (social proof) to increase viewer trust, while giving us the option to replace the “generic” CTA, with a less committal CTA of “See TradingHub in Action”. While it could be argued that this CTA feels less conversion-orientated, on balance, the user continuing to read through a case study of TradingHub’s tools in action does feels more natural considering this is a homepage.
Concluding with the final recommendation in this section, it’s interesting to note that DeepSeek appears to repeat ChatGPT’s error of hallucinating non-existent form issues. One explanation for this is that the guidance provided i.e. “Reduce fields to 3-4 essentials” and “Add a privacy reassurance” is so generic that these tips have likely been included and repeated en masse within a significant proportion of the training data.

Key takeaway 🥡 4 out of 5 points – a point docked due to DeepSeek also hallucinating assessment of the form.
The last recommendation section contains what feels like two reasonable and effective suggestions, while the last recommendation seems unnecessary.
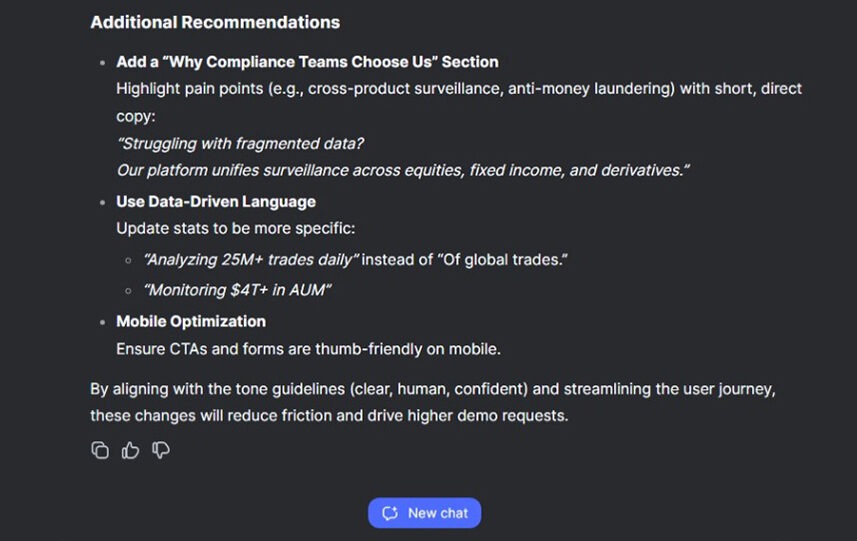
Key takeaway 🥡 2 out of 3 points.
In conclusion
ChatGPT Final Score: 5 out of 14 points (35% output quality)
DeepSeek Final Score: 10 out of 14 points (71% output quality)
To summarise, ChatGPT omitted key issues that would have provided greater context to the user and suggested fairly basic on-page and design recommendations. DeepSeek, however, effectively referenced the Tone of Voice Guidelines PDF and included “Before” and “After” sections for easy comparison. DeepSeek also suggested using bullet lists and incorporating customer testimonials to increase viewer trust. Additionally, DeepSeek recommended actionable and considered steps which, based on my personal experience, feel they would improve the effectiveness of the page in relation to conversion and UX. While DeepSeek repeated the form hallucination which was present in ChatGPT’s output, it provided overall useful suggestions.
In conclusion, ChatGPT received a final score of 5 out of 14 points, while DeepSeek achieved 10 out of 14 points, indicating a higher quality of output from DeepSeek.


